











As a 10-year-old growing up in Shanghai, Jun-Yan Zhu often avoided homework with furtive doodling. He’d sketch comics or movie characters in pencil, then erase the evidence before his mother saw it. Much as he loved drawing, however, he wasn’t very good at it. He dreamed of a world where everyone, even those who lacked the talent, could easily communicate in pictures.
Now a doctoral student in UC Berkeley’s Department of Electrical Engineering and Computer Sciences, Zhu is using technology to help make his childhood dream a reality for us all. His research projects have yielded potential applications from improving online search and e-commerce to art and fashion. Not to mention selfies.
Zhu says his goal is simply that “with a few clicks, everyone can show other people what they are thinking.”
“…. We are trying to make people uniformly visually literate.”
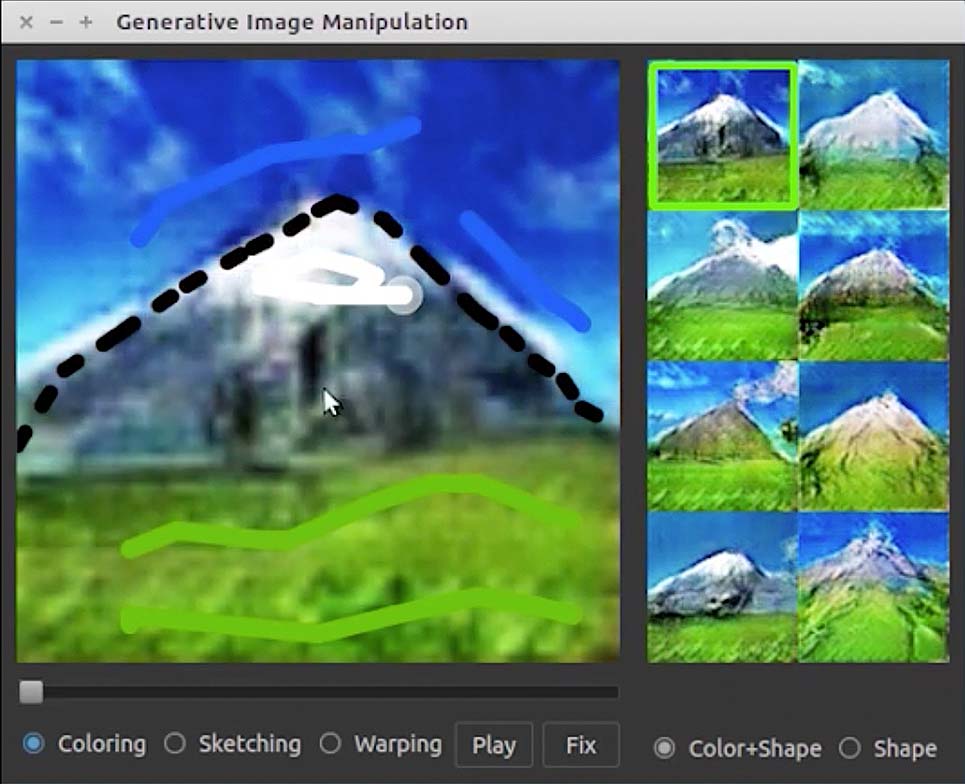
To make that happen, he has applied the tools of machine learning, a subfield of artificial intelligence, to computer graphics. In the most recent project Zhu led, his team developed software that lets users easily create realistic images from the crudest brushstrokes. Just by scribbling on screen a couple of green lines, an inverted gray V, and a smear of blue, a user can produce an idealized alpine scene—a glade backed by a soaring mountain peak, clear skies beyond—in nearly real-time. Other programs have used AI to generate such naturalistic images, but this goes a step further, allowing a human to interact with the program to guide the process.
“We are all consumers of visual content, but there is still this asymmetry where not that many of us are creators,” says Zhu’s advisor, computer science professor Alexei Efros. “You can think of this as providing training wheels for visual content creation…. We are trying to make people uniformly visually literate.”
One potential application of the technology is better online search: Say you spot a decent pair of shoes online but wish they were blue and had tassels or lower heels. It’s not easy to convey this in search terms, and most of us have no way of expressing it visually, but a program like Zhu’s could allow you to transform the product photo to depict your ideal pair of kicks, then, using image search, find the closest match available online.
Improved online shopping could also follow from an earlier project of Zhu’s called AverageExplorer. Two years ago, his team created an interactive framework that lets users quickly explore large image collections by condensing them into “average images.” “A human being can only see a small portion of the photos that exist. This is a visualization tool to understand millions of images through a single image,” Zhu says. AverageExplorer also allowed users to edit the average image, say with a digital brush or eraser, to create a “weighted average” based on the features they deemed important. An online shopper, for example, could use the technology to turn a product photo of loafers into flats by removing the shoe tongue.
One of Zhu’s favorite examples displays the average image of various cat breeds. (In his spare time, Zhu, who adopted a cat named Aquarius in 2014, curates a collection of computer science papers that include images of the felines.)
Yet another project came about when Zhu noticed how tough it was to take good selfies. To help, his team combined crowdsourcing and machine learning tools to train a computer program to give users feedback on their portrait expressions. The program can select your most attractive look, across various levels of “seriousness,” from a large number of portraits. Using an app called “Mirror Mirror,” it can also advise you on how to adjust your expression—eventually they hope it can even train you to replicate your most winning expression every time.
Zhu started working in the field of computer visualization at Beijing’s Tsinghua University, where he earned a computer science degree in 2012. While there, he interned with Microsoft Research Asia, where he worked on programs to detect objects in digital images—say, a cat or a dog, or more critically, cancer tissue. After enrolling in a Ph.D. program at Carnegie Mellon University, he followed Efros, his thesis advisor there, to Berkeley in 2013.
Facebook is covering Zhu’s tuition and paying him a stipend through a graduate fellowship. His research has also been supported by grants from Google, Adobe, eBay and Intel. None of this gives the companies rights to his work, however, and all of his code is open source for now. Zhu insists he’s more interested in sharing the technology than profiting from it. “If someone can make money from the techniques, I’m perfectly happy, but I want it to be accessible to everyone,” he says.
Zhu relates the emails received from members of GitHub, the online developer community, thanking him for unleashing their inner artist. “The kind of enthusiasm that comes from generating an image with a few strokes is the most exciting part for me.”








